

Chi Wang
Founder of AutoGen (now AG2) & FLAML
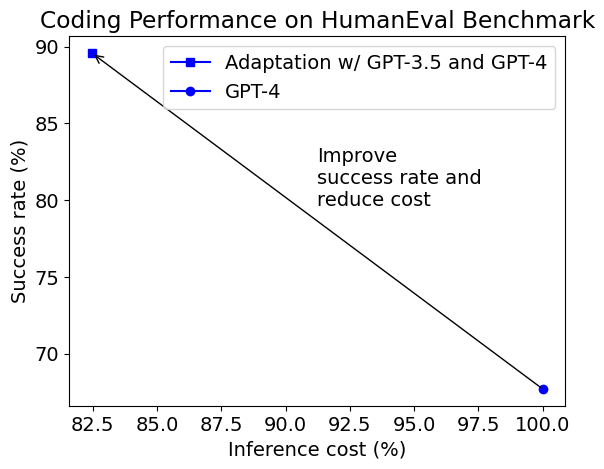
- A case study using the HumanEval benchmark shows that an adaptive way of using multiple GPT models can achieve both much higher accuracy (from 68% to 90%) and lower inference cost (by 18%) than using GPT-4 for coding.
Observations
- GPT-3.5-Turbo can already solve 40%-50% tasks. For these tasks if we never use GPT-4, we can save nearly 40-50% cost.
- If we use the saved cost to generate more responses with GPT-4 for the remaining unsolved tasks, it is possible to solve some more of them while keeping the amortized cost down.
Solution
Combining these observations, we can design a solution with two intuitive ideas:- Make use of auto-generated feedback, i.e., code execution results, to filter responses.
- Try inference configurations one by one, until one response can pass the filter.
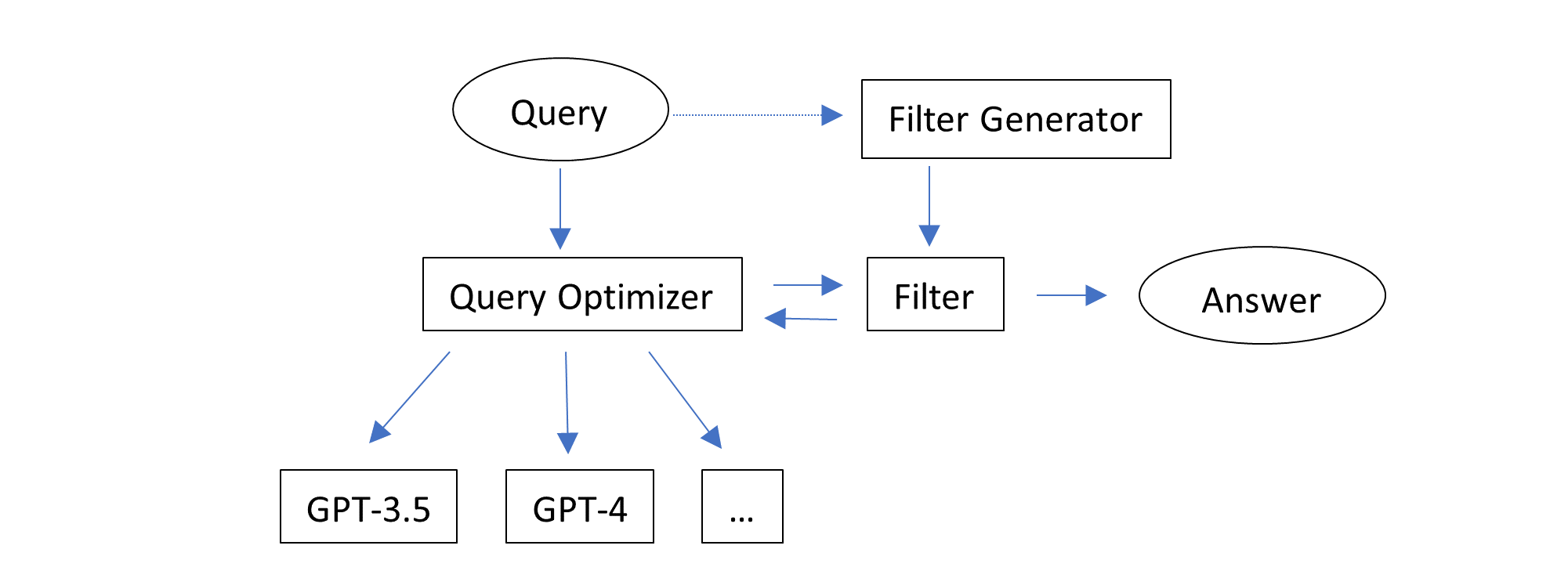
- GPT-3.5-Turbo, n=1, temperature=0
- GPT-3.5-Turbo, n=7, temperature=1, stop=[“\nclass”, “\ndef”, “\nif”, “\nprint”]
- GPT-4, n=1, temperature=0
- GPT-4, n=2, temperature=1, stop=[“\nclass”, “\ndef”, “\nif”, “\nprint”]
- GPT-4, n=1, temperature=1, stop=[“\nclass”, “\ndef”, “\nif”, “\nprint”]
Experiment Results
The first figure in this blog post shows the success rate and average inference cost of the adaptive solution compared with default GPT-4. The inference cost includes the cost for generating the assertions in our solution. The generated assertions are not always correct, and programs that pass/fail the generated assertions are not always right/wrong. Despite of that, the adaptive solution can increase the success rate (referred to as pass@1 in the literature) from 68% to 90%, while reducing the cost by 18%. Here are a few examples of function definitions which are solved by different configurations in the portfolio.- Solved by GPT-3.5-Turbo, n=1, temperature=0
- Solved by GPT-3.5-Turbo, n=7, temperature=1, stop=[“\nclass”, “\ndef”, “\nif”, “\nprint”]: the
vowels_countfunction presented earlier. - Solved by GPT-4, n=1, temperature=0:
- Solved by GPT-4, n=2, temperature=1, stop=[“\nclass”, “\ndef”, “\nif”, “\nprint”]:
- Solved by GPT-4, n=1, temperature=1, stop=[“\nclass”, “\ndef”, “\nif”, “\nprint”]:
- Our adaptive solution has a certain degree of fault tolerance.
- The success rate and inference cost for the adaptive solution can be further improved if correct example test cases are used.
Discussion
Our solution is quite simple to implement using a generic interface offered in autogen, yet the result is quite encouraging. While the specific way of generating assertions is application-specific, the main ideas are general in LLM operations:- Generate multiple responses to select - especially useful when selecting a good response is relatively easier than generating a good response at one shot.
- Consider multiple configurations to generate responses - especially useful when:
- Model and other inference parameter choice affect the utility-cost tradeoff; or
- Different configurations have complementary effect.
autogen uses a technique EcoOptiGen to support inference parameter tuning and model selection.
There are many directions of extensions in research and development:
- Generalize the way to provide feedback.
- Automate the process of optimizing the configurations.
- Build adaptive agents for different applications.
For Further Reading
- Documentation about
autogenand Research paper. - Blog post about a related study for math.