# Ensure the OPENAI_API_KEY is set in the environment
llm_config = {"model": "gpt-4o", "api_type": "openai", "cache_seed": None}
# Create agents for the NVIDIA and AMD documents
# Each agent has a unique collection_name so that data and queries are run in different vector store spaces
nvidia_agent = DocAgent(
name="nvidia_agent",
llm_config=llm_config,
collection_name="nvidia-demo",
)
amd_agent = DocAgent(
name="amd_agent",
llm_config=llm_config,
collection_name="amd-demo",
)
# A financial analyst agent who will direct the DocAgents to ingest documents and answer questions
# The financial analyst will also summarize the results and terminate the conversation
analyst = ConversableAgent(
name="financial_analyst",
system_message=(
"You are a financial analyst working with two specialist agents, amd_agent who handles all AMD documents and queries, and nvidia_agent who handles all NVIDIA documents and queries. "
"Each agent knows how to load documents and answer questions from the document regarding their respective companies. "
"Only mention one of the two agents at a time, prioritize amd_agent. You will be able to engage each agent separately in subsequent iterations. "
"CRITICAL - Work with ONLY ONE agent at a time and provide (a) an indication for them to take action by saying '[Next to speak is ...]' together with (b) documents they need to ingest and (c) queries they need to run, if any. "
"DO NOT provide instructions that include the mention of both agents in the one response. "
"When all documents have been ingested and all queries have been answered, provide a summary and add 'TERMINATE' to the end of your summary. "
"The summary should contain detailed bullet points (multiple per query if needed) and grouped by each query. After the summary provide a one line conclusion. "
"Add the term '(This is not financial advice)' at the end of your conclusion. "
"If there are errors, list them and say 'TERMINATE'. "
"If there are no errors, do not say 'TERMINATE' until each agent has run their queries and provided their answers."
),
is_termination_msg=lambda x: x.get("content", "") and "terminate" in x.get("content", "").lower(),
llm_config=llm_config,
)
# Initiate the swarm (change the file paths in the messages if needed)
result, _, _ = initiate_swarm_chat(
initial_agent=analyst,
agents=[analyst, nvidia_agent, amd_agent],
messages=(
"Use the amd_agent to load AMD's 4th quarter 2024 report from "
"./docagent/AMDQ4-2024.pdf "
"and use the nvidia_agent to load NVIDIA's 3rd quarter 2025 report from "
"./docagent/NVIDIAQ3-2025.pdf. "
"Ask 'amd_agent' to ingest the AMD document and answer two queries (a) what AMD did in regards to AI and (b) what was the Q4 2024 GAAP revenue."
"Ask 'nvidia_agent' to ingest the NVIDIA document and answer two queries (a) what NVIDIA did in regards to AI and (b) what was Q3 2025 GAAP revenue."
),
swarm_manager_args={
"llm_config": llm_config,
"system_message": "You are managing a financial analyst and two specialist company agents. After amd_agent or nvidia_agent, select the financial_analyst to speak next.",
"is_termination_msg": lambda x: x.get("content", "") and "terminate" in x.get("content", "").lower(),
},
after_work=AfterWorkOption.SWARM_MANAGER,
)
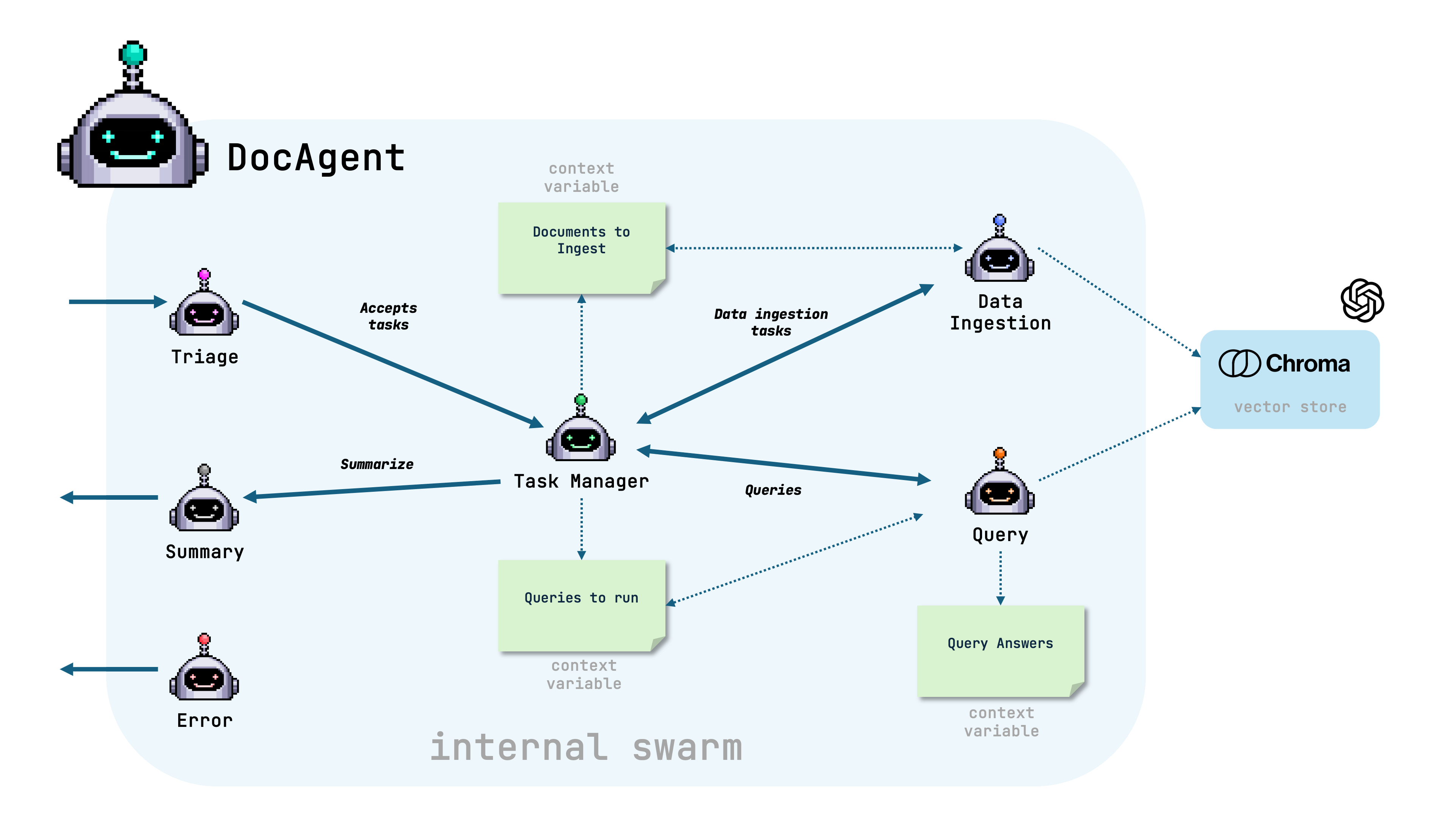 Before jumping into the code, let’s have a look at the swarm inside the
DocAgent.
The swarm contains the following agents:
Before jumping into the code, let’s have a look at the swarm inside the
DocAgent.
The swarm contains the following agents: