Notebooks
Language Agent Tree Search
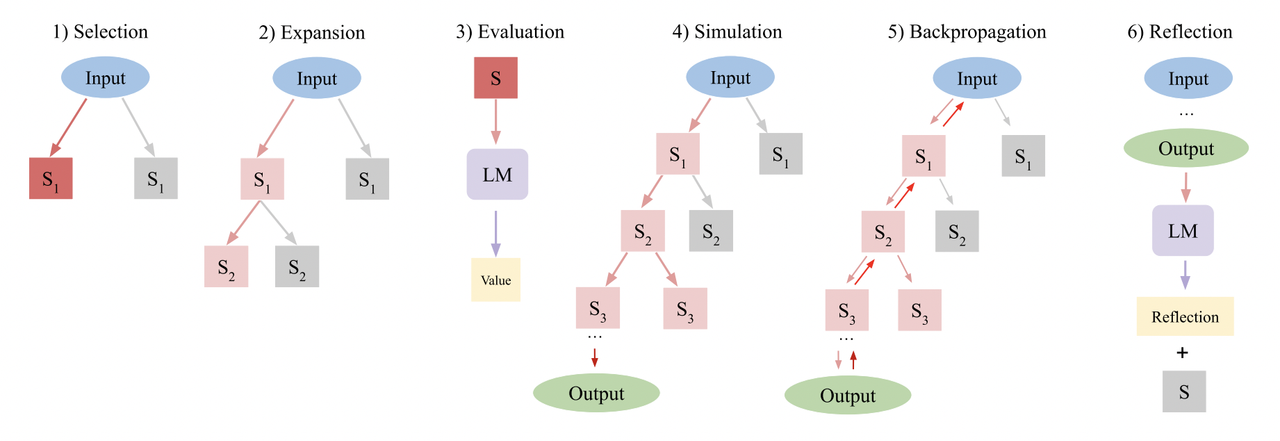
Language Agent Tree Search.
- Select: pick the best next state to progress from, based on its aggregate value.
- Expand and simulate: sample n potential actions to take and execute them in parallel.
- Reflect + Evaluate: observe the outcomes of these actions and score the decisions based on reflection (and possibly external feedback if available)
- Backpropagate: update the scores of the root trajectories based on the outcomes.
Configure logging
Set environment variables
Prerequisites
Installautogen (for the LLM framework and agents)
Required packages: autogen
Please ensure these packages are installed before running this script
Directly create the config_list with the API key
Reflection Class
The reflection chain will score agent outputs based on the decision and the tool responses.Tree State
LATS is based on a (greedy) Monte-Carlo tree search. For each search steps, it picks the node with the highest “upper confidence bound”, which is a metric that balances exploitation (highest average reward) and exploration (lowest visits). Starting from that node, it generates N (5 in this case) new candidate actions to take, and adds them to the tree. It stops searching either when it has generated a valid solution OR when it has reached the maximum number of rollouts (search tree depth).Define Language Agent
Our agent will have three primary LLM-powered processes:- Reflect: score the action based on the tool response.
- Initial response: to create the root node and start the search.
- Expand: generate 5 candidate “next steps” from the best spot in the current tree
Tools
For our example, we will give the language agent a search engine. Define the UserProxyAgent with web search / tool-use capabilityReflection
Self-reflection allows the agent to bootstrap, improving its future responses based on the outcome of previous ones. In agents this is more powerful since it can use external feedback to improve.Initial Response
We start with a single root node, generated by this first step. It responds to the user input either with a tool invocation or a response.Create Autogen agents
Define a function to create the initial prompt
Function to generate initial response
Example usage of the generate_initial_response function
Starting Node
We will package up the candidate generation and reflection in a single node of our graph. This is represented by the following function:Define the function to generate the initial response
Candidate Generation
The following code prompts the same LLM to generate N additional candidates to check. This generates N candidate values for a single input to sample actions from the environmentCandidate generation node
We will package the candidate generation and reflection steps in the following “expand” node. We do all the operations as a batch process to speed up execution.Create Tree
With those two nodes defined, we are ready to define the tree. After each agent step, we have the option of finishing.Example usage of the LATS algorithm with Autogen
List of example questions
Run LATS algorithm for each question
Conclusion
Congrats on implementing LATS! This is a technique that can be reasonably fast and effective at solving complex agent tasks. A few notes that you probably observed above:- While LATS is effective, the tree rollout process can require additional inference compute time. If you plan to integrate this into a production application, consider streaming intermediate steps to allow users to see the thought process and access intermediate results. Alternatively, you could use it to generate fine-tuning data to enhance single-shot accuracy and avoid lengthy rollouts. The cost of using LATS has significantly decreased since its initial proposal and is expected to continue decreasing.
- The effectiveness of the candidate selection process depends on the quality of the rewards generated. In this example, we exclusively use self-reflection as feedback, but if you have access to external feedback sources (such as code test execution), those should be incorporated as suggested above.