- Arize Phoenix to provide transparency using the OpenTelemetry standard
- FalkorDB agent using a GraphRAG database of restaurants and attractions
- Structured Output agent that will enforce a strict format for the accepted itinerary
- Routing agent that utilises the Google Maps API to calculate distances between activities
- Swarm orchestration utilising context variables
This notebook has been updated as swarms can now accommodate any ConversableAgent.
Initialize Python environment
- FalkorDB’s GraphRAG-SDK is a dependency for this notebook
- Please ensure you have Pydantic version 2+ installed
Install Docker Containers
Note: This may require a Docker Compose file to get it to work reliably.FalkorDB
- UI endpoint: http://localhost:3000/graph
- sample query:
match path = ()-[]-() return path
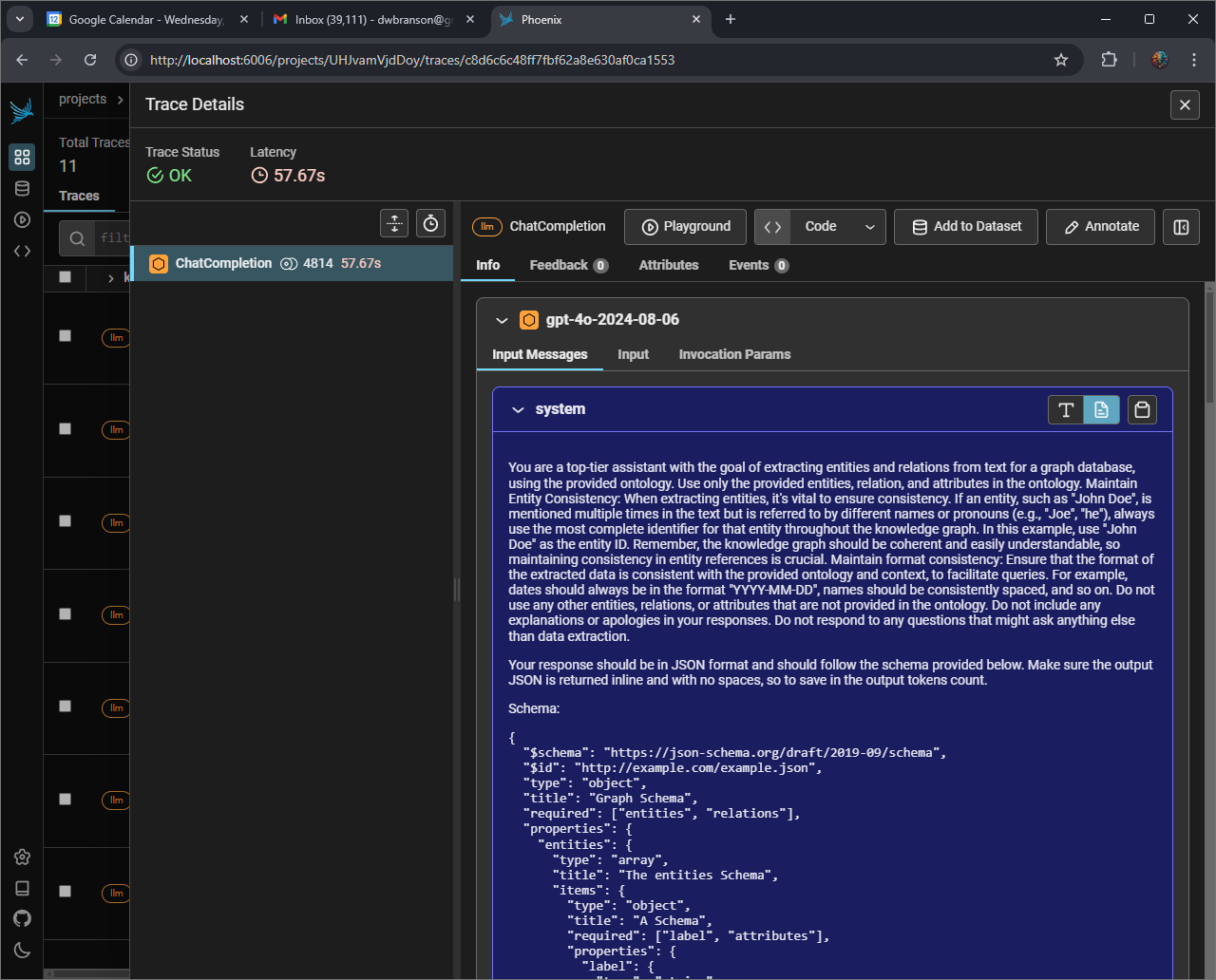
Arize Phoenix
- UI endpoint: http://localhost:6006
Arize Phoenix: setup and configuration
Google Maps API Key
To use Google’s API to calculate travel times, you will need to have enabled theDirections API in your Google Maps Platform. You can get
an API key and free quota, see
here
and here for more
details.
Once you have your API key, set the environment variable
GOOGLE_MAP_API_KEY to this value.
NOTE: If the route planning step is failing, it is likely an environment
variable issue which can occur in Jupyter notebooks. The code in the
update_itinerary_with_travel_times and _fetch_travel_time functions
below could be enhanced to provide better visibility if these API calls
fail. The following code cell can assist.
Set Configuration and OpenAI API Key
Create a OAI_CONFIG_LIST file in the AG2 projectnotebook
directory based on the OAI_CONFIG_LIST_sample file from the root
directory.
By default, FalkorDB uses OpenAI LLMs and that requires an OpenAI key in
your environment variable OPENAI_API_KEY.
You can utilise an OAI_CONFIG_LIST file and extract the OpenAI API key
and put it in the environment, as will be shown in the following cell.
Alternatively, you can load the environment variable yourself.
Prepare the FalkorDB GraphRAG database
Using 3 sample JSON data files from our GitHub repository, we will create a specific ontology for our GraphRAG database and then populate it. Creating a specific ontology that matches with the types of queries makes for a more optimal database and is more cost efficient when populating the knowledge graph.Create Ontology
Entities: Country, City, Attraction, Restaurant Relationships: City in Country, Attraction in City, Restaurant in CityInitialize FalkorDB and Query Engine
Remember: Change your host, port, and preferred OpenAI model if needed (gpt-4o-mini and better is recommended).Pydantic model for Structured Output
Utilising OpenAI’s Structured Outputs, our Structured Output agent’s responses will be constrained to this Pydantic model. The itinerary is structured as: Itinerary has Day(s) has Event(s)Google Maps Platform
The functions necessary to query the Directions API to get travel times.Swarm
Context Variables
Our swarm agents will have access to a couple of context variables in relation to the itinerary.Agent Functions
We have two functions/tools for our agents. One for our Planner agent to mark an itinerary as confirmed by the customer and to store the final text itinerary. This will then transfer to our Structured Output agent. Another for the Structured Output Agent to save the structured itinerary and transfer to the Route Timing agent.Agents
Our Swarm agents and a UserProxyAgent (human) which the swarm will interact with.Hand offs and After works
In conjunction with the agent’s associated functions, we establish rules that govern the swarm orchestration through hand offs and After works. For more details on the swarm orchestration, see the documentation.Run the swarm
Let’s get an itinerary for a couple of days in Rome.Bonus itinerary output
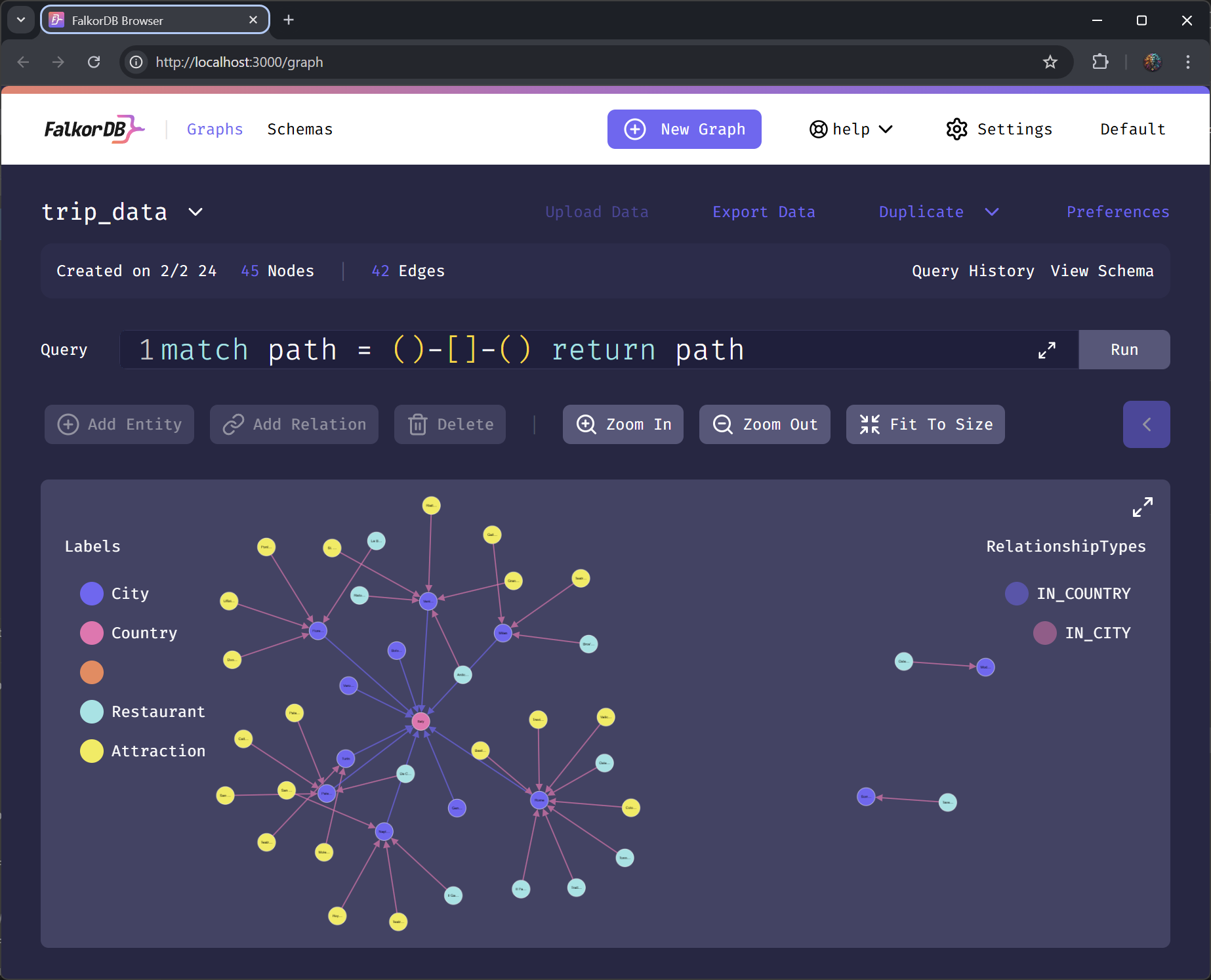
Review FalkorDB Graph
- UI endpoint: http://localhost:3000/graph
- sample query:
match path = ()-[]-() return path
trip_data graph is actually
empty…
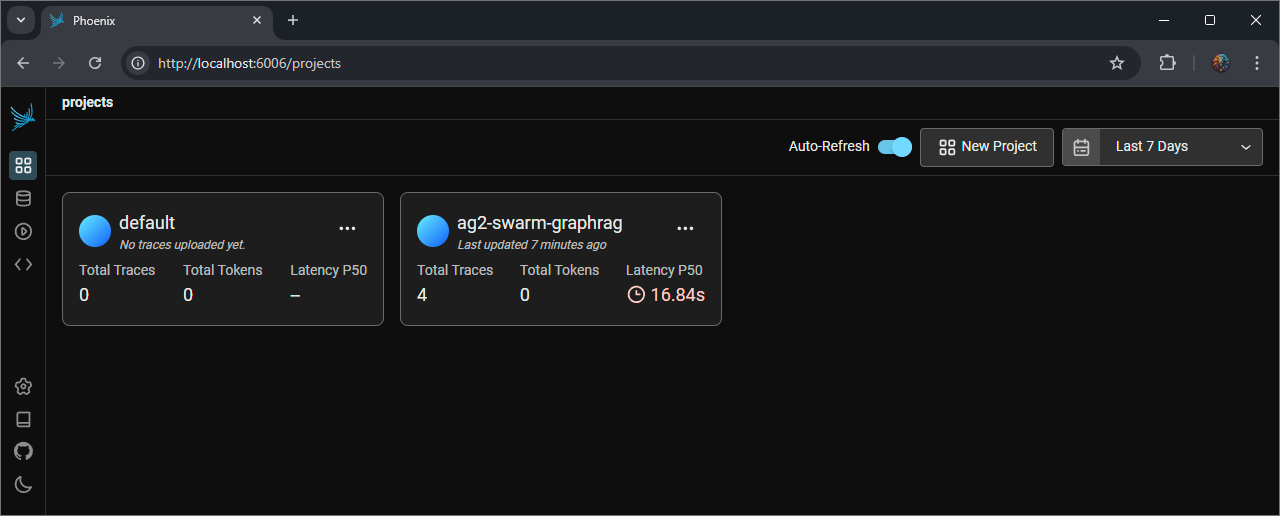
Review Arize Phoenix Telemetry Info
- UI endpoint: http://localhost:6006
Card View
List View

Detail View - Route Timing Agent - LLM error
NOTE: this was based on LLM issues at the time of the test. A key reason why telemetry information is so valuable.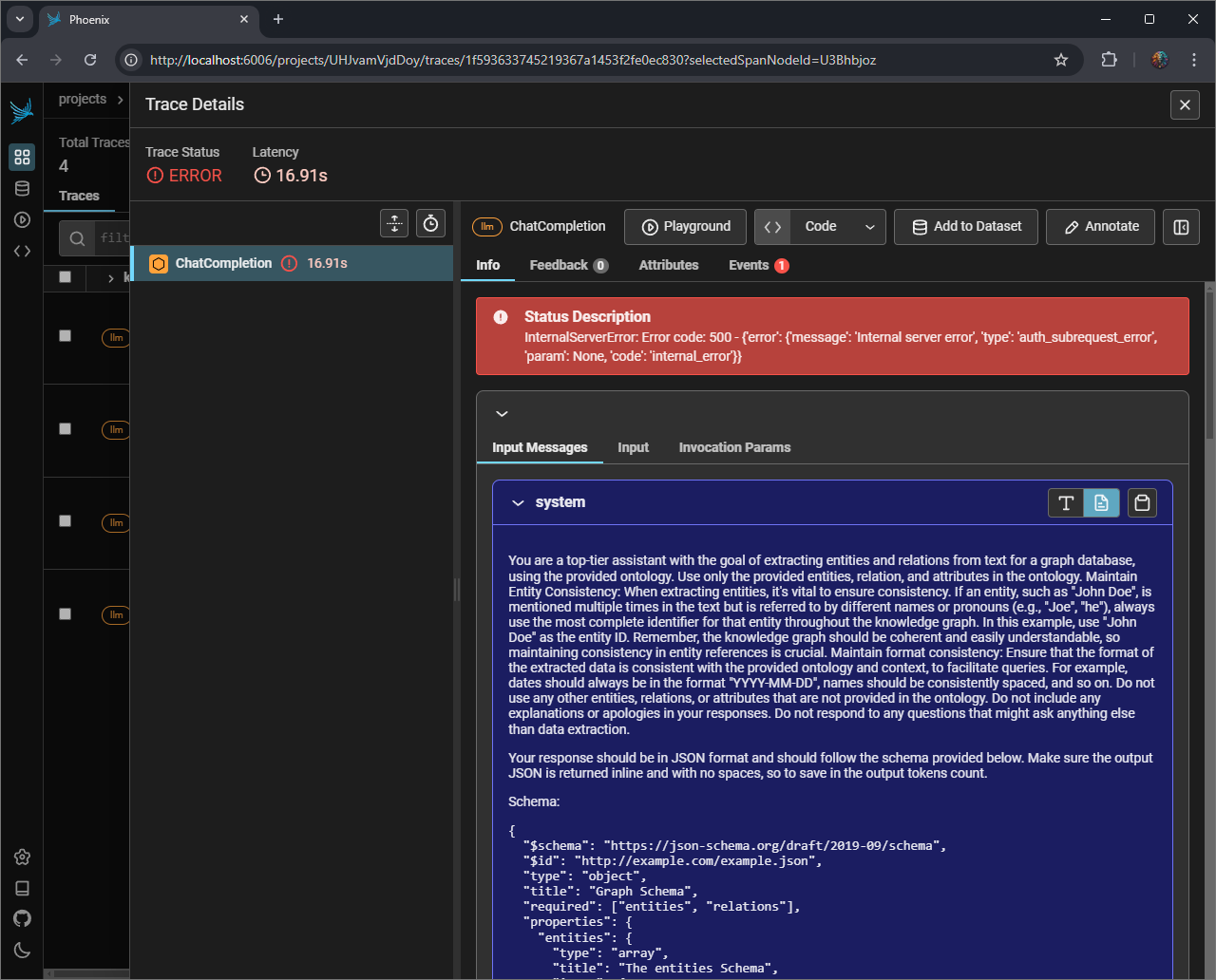
Detail View - Route Timing Agent - working normally